
Redis 란?
Redis(Re mote Di ctionary S erver)는 오픈 소스 인메모리 데이터 저장소 및 캐싱 시스템으로, 다양한 데이터 구조를 지원하며 높은 성능과 속도를 제공한다.
- 인메모리 데이터베이스
- Redis는 모든 데이터를 메모리에 저장하므로 빠른 데이터 액세스를 제공하며, 데이터베이스 작업 및 캐싱에 특히 유용하다.
- 다양한 데이터 구조
- Redis는 문자열, 리스트, 해시, 집합, 정렬된 집합 등 다양한 데이터 구조를 지원하므로 다양한 애플리케이션에서 활용할 수 있다.
- 지속성
- Redis는 디스크에 데이터를 저장하고 복구할 수 있는 기능을 제공하여 데이터의 지속성을 보장한다.
- 높은 가용성
- Redis는 마스터-슬레이브 복제 및 클러스터링을 지원하여 고가용성 아키텍처를 구축할 수 있다.
- 풍부한 클라이언트 라이브러리
- Redis는 다양한 프로그래밍 언어를 지원하는 클라이언트 라이브러리를 제공하므로 다양한 플랫폼 및 언어에서 사용할 수 있다.
- Pub/Sub 메커니즘
- Redis는 Publish/Subscribe 메커니즘을 지원하여 이벤트 기반 메시지 처리에 적합하다.
- 트랜잭션과 원자성
- Redis는 다중 명령을 하나의 트랜잭션으로 그룹화하고, 실행 중에 다른 클라이언트의 명령을 차단하지 않는 원자성을 제공한다.
Redis는 캐싱, 세션 관리, 리더보드, 대기열 처리 등 다양한 용도로 사용된다. 또한, Key-Value 타입의 NoSQL 데이터베이스로도 활용되는데, 데이터 크기가 메모리에 맞아야 하며, 지속성을 필요로 하는 경우에는 주기적으로 디스크에 스냅샷을 저장해야 한다.
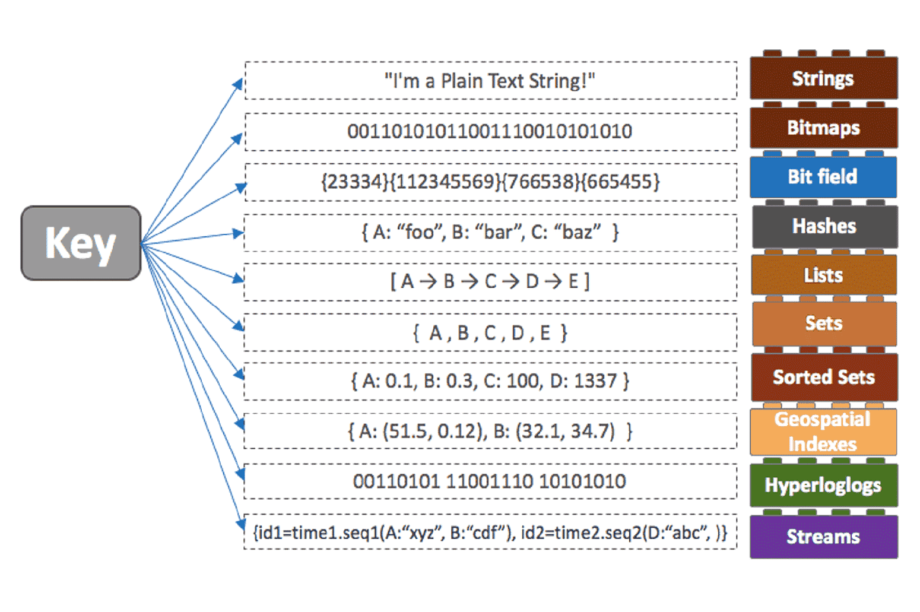
Redis Data Structures/Collection
- Redis 는 다양한 데이터 구조를 제공하고 있다.
- 아래 그림을 바탕으로 Redis에서 지원하는 데이터 구조의 간략한 특징은 아래와 같다.
1. String : 일반적인 문자열 저장하며, 단순 증감 연산에 유리함. String으로 될 수 있는 binary data도, JPEG 이미지도 저장 가능함.
2. Bitmaps : string의 변형으로 bit 단위 연산 가능함. 저장공간 절약에 유리함.
3. Bit field : 오프셋 지정을 통한 Bit 연산을 수행함.
4. Hashes : value와 연관된 필드로 구성된 맵. 모든 필드와 값은 모두 문자열로 구성
5. Lists : 입력 순서에 따라 정렬된 문자열의 집합. 기본적인 linked list 형태
6. Sets : 고유하고 정렬되지 않은 문자열의 집합.
7. Soreted sets : Set에 score라는 필드가 추가된 데이터 형으로 Sorted Set은 Set의 특성을 그대로 가지며 추가적으로 저장된 member들의 순서도 관리함. 유저 랭킹 보드서버 같은 구현에서 유리함.
8. Geospatial Indexes : 지리정보를 담기 위한 데이터 타입
9. HyperLogLogs : 집합의 카디널리티를 추정하기 위해 사용되는 확률적 데이터 구조.
10. Streams : 추상 로그 데이터 유형을 제공하는 append-only 자료구조
각 데이터 타입에 따라 데이터를 생성하고 조회하고 삭제하는 절차를 다루는 명령어는 차이가 있다. 타입에 따른 데이터를 생성, 조회, 수정, 삭제하는 명령어는 아래에서 간략하게 다룬다.
Redis 설치 (RedHat 계열 Linux)
$ yum install redis // yum 리포지토리를 통해 redis 설치
$ systemctl start redis // redis 시작
$ systemctl enable redis // 부팅시 자동 시작하도록 설정
$ redis-cli -h 192.168.0.5 // redis 접속
# 옵션
# -h : 호스트 네임 (기본값: 127.0.0.1)
# -p : 포트 번호 (기본값: 6380)
# -n : 데이터베이스 번호 (기본값: 0)
# -a: 접속 비밀번호
# ping: 연결 테스트
#
Redis 환경 설정
- 외부 접속 허용
# redis.conf 파일에서 bind를 0.0.0.0으로 변경
$ vim /etc/redis.conf
# 외부에서 접속 가능한지 확인
$ netstat -nlpt|grep 6379
# * netstat: 네트워크 접속, 라우팅 테이블, 네트워크 인터페이스의 통계 정보를 보여주는 도구
- 명령어 변경
- Redis를 실제 운영환경에서 운영할 때 주의해서 사용해야 하는 명령어가 있다.
- 예를 들면 FLUSHDB(현재 DB의 모든 데이터 삭제), FLUSHALL(모든 DB의 모든 데이터 삭제) ,KEYS (패턴에 일치하는 키 목록 반환), DEBUG(Redis 서버의 내부 디버깅) ,SAVE (데이터 스냅샷 디스크에 저장) 가 있다.
- rename-command 명령어를 통해 관리자 이외에 미리 정의된 명령어를 사용하지 못하도록 설정한다.
# redis.conf 파일에서 rename-command 명령어 입력
$ vim /etc/redis.conf
rename-command FLUSHDB [별칭 부여]
rename-command FLUSHALL [별칭 부여]
rename-command KEYS [별칭 부여]
rename-command DEBUG [별칭 부여]
rename-command SAVE [별칭 부여]
Redis Key
- Redis의 key는 binary safe 이다. Text 문자열부터 JPG와 같은 Binary 파일까지 Redis의 Key로 지정할 수 있다. (빈 문자열도 가능)
- Key의 최대 허용 크기는 512MB이다.
- Redis의 Key에 대한 규칙은 아래와 같다.
1. 과도하게 길이가 긴 Key를 생성하지 않는 것이 좋다.
: 과도하게 길이가 긴 Key는 데이터 집합에서 Key를 조회하기 위해 많은 리소스를 요구할 수 있다. 길이가 긴 Key 생성이 필요할 경우 데이터를 해싱하는 방법이 더 나은 방법이다.
2. 가독성이 떨어지는 짧은 Key를 생성하지 않는 것이 좋다.
: 짧은 Key는 리소스를 덜 사용하겠지만 관리 측면에서 효율적이지 않다. 예를 들어 "u1000flw"와 같은 키를 작성하는 대신 "user:1000:followers"와 같이 네임스페이스 구분자(:)를 포함하여 작성하는 것이 더 가독성이 좋으며, 추가된 공백은 키 객체와 값 객체에 사용되는 공간에 비해 미미하다.
3. 일관되는 네이밍을 하는 것이 좋다.
: 일관되는 Key 네이밍을 하는 것이 관리 측면에서 더 효율적이다. 예를 들어 "user:1000"과 같이 "object-type:id" 형식을 사용하는 것이 좋다. 여러 단어 필드에는 점(.)이나 대시(-)를 사용하는 것이 일반적이며, 예를 들어 "comment:4321:reply.to"나 "comment:4321:reply-to"와 같이 사용한다.
데이터 구조별 명령어
https://sjh836.tistory.com/178
1. String
- 이진 데이터를 포함한 일반적인 문자열 저장한다. (ex. 이미지 파일, 엑셀 파일, 사용자 ID, 사용자 토큰 및 세션 등등)
- 데이터 추가 / 수정 [O(1) / O(N)]
# 단건
> SET <key> <value>
# 복수
> MSET <key1> <value1> <key2> <value2>
- 데이터 조회 [O(1) / O(N)]
# 단건
> GET <key>
# 복수
> MGET <key1> <key2> ... <keyN>
- 데이터 삭제 [O(1) / O(N)]
# 단건
> DEL <key>
# 복수
> DEL <key1> <key2> ... <keyN>
2. Hashes
- value와 연관된 필드로 구성된 맵으로 마치 관계형 DB의 스키마처럼 사용할 수 있다. (ex. 이메일, 패스워드, 나이, 별칭과 같이 사용자의 정보를 담는 목적으로 사용 할 수 있음)
- 데이터 추가 / 수정 [O(1) / O(N)]
# 단건
> HSET <key> <field> <value>
# 복수
> HMSET <key> <field1> <value1> <field2> <value2> ... <fieldN> <valueN>
- 데이터 조회 [O(1) / O(N)]
# 해시의 특정 필드
> HGET <key> <field># 해시의 모든 필드
> HGETALL <key>
- 데이터 삭제
1. 해시 전체 삭제 [O(1) / O(N)]
# 단건
> DEL <key>
# 복수
> DEL <key1> <key2> ... <keyN>
2. 특정 필드 삭제 [O(N)]
# 단건
> HDEL <key> <field1>
# 복수
> HDEL <key> <field1> <field2>
3. Lists
- 입력 순서에 따라 정렬된 문자열의 집합을 저장한다. (ex. 이메일 큐, 로그, 작업 등의 목적으로 사용할 수 있다.)
- 데이터 추가 / 수정
1. 오른쪽 끝에 추가
# 단건
> RPUSH <key> <item>
# 복수
> RPUSH <key> <item1> <item2> <item3> ... <itemN>
2. 왼쪽 끝에 추가
# 단건
> LPUSH <key> <item>
# 복수
> LPUSH <key> <item1> <item2> <item3> ... <itemN>
- 데이터 조회
# 모든 아이템 조회
> LRANGE <key> 0 -1 #0은 시작을 의미, -1은 마지막을 의미
# 데이터(인덱스) 크기 조회
> LLEN <key>
# 단일 아이템 조회
> LINDEX <key> <index>
# 복수(범위) 아이템 조회
> LRANGE <key> <start index> <end index> # 첫 인덱스는 0부터 시작
- 데이터 삭제
# 단일 아이템 삭제
> LPOP <key> # 리스트 왼쪽 끝에서 아이템 삭제
> RPOP <key> # 리스트 오른쪽 끝에서 아이템 삭제
# 복수 아이템 삭제
> LREM <key> <number> <value> # number 만큼 지정된 value를 삭제
> LTRIM <key> <start index> <end index> # start index와 end index의 범위 아이템만 남기고 모든 아이템 삭제
# 모든 아이템 삭제
> LTRIM <key> 0 0 # 모든 아이템을 삭제
# List 삭제
> DEL <key>
4. Sets
- 고유(중복되지 않는)하고 정렬되지 않은 문자열을 저장한다.(ex. 태그, 친구 목록, 추천, 사용자 ID 등에서 사용할 수 있다.)
- 데이터 추가 / 수정
# 단건
> SADD <key> <item>
# 복수
> SADD <key> <item1> <item2> ... <itemN>
- 데이터 조회
# sets의 모든 멤버 조회
> SMEMBERS <key>
# 멤버의 존재 확인
> SISMEMBER <key> <item>
- 데이터 삭제
# 복수 멤버 삭제
> SREM <key> <item1> <item2> ... <itemN>
# 임의의 멤버 삭제
> SPOP <key>
# sets 삭제
> DEL <key>
5. Streams
- 추상 로그 데이터 유형을 저장한다. (ex. 로그, 실시간 데이터 피드, 알림 등에서 사용할 수 있다.)
- 데이터 추가 / 수정
# 데이터 추가
> XADD * <key> <field1> <value1> <field2> <value2> ... <fieldN> <valueN> # * 는 아이템의 ID를 현재 시간으로 지정
# 데이터 수정 (동일한 ID를 이용하여 데이터를 덮어씀)
> > XADD 1609832400000 <key> ... [생략]
- 데이터 조회
# 모든 데이터 읽기
> XREAD STREAMS mystream 0
# 이전 데이터 조회
> XREAD STREAMS mystream 1609832400000 # 1609832400000 부터 이전 데이터
6. 모든 Key 조회
> keys *
7. 모든 Key - value 삭제
> flushall # 모든 DB의 모든 데이터 삭제
> flushdb # 현재 DB의 모든 데이터 삭제
TTL(Time To Live) 설정
- Redis에서 특정 키의 유효 기간(만료 시간)을 설정하여 Redis에서 자동으로 키의 유효 기간이 만료되면 삭제되도록 할 수 있다.
- 만료 시간 지정을 위해 EXPIRE 명령어를 이용한다.
예를 들어 MY_KEY라는 이름을 갖고 있는 Key의 만료 시간을 지정하려면 Redis에서 EXPIRE 명령어를 이용하여 아래와 같이 설정한다.
> EXPIRE [MY_KEY] 3600 # 지정단위는 초단위 1시간 = 60 X 60
위와 같은 명령어로 만료 시간을 지정하면 자동으로 삭제된다. 만료되어 데이터가 삭제되었는지 확인하기 위해서는 TTL 명령어를 이용하여 데이터 만료를 확인한다.
> TTL [MY_KEY]
참고 사이트
[1] [Linux] CentOS7 Redis 설치
https://sic-dev.tistory.com/60
[2] Redis Data Structures
https://redis.com/redis-enterprise/data-structures/
[3] Redis 데이터 타입(Data Type) 및 데이터 입력 조작 삭제
https://hoing.io/archives/5341
[4] [Redis Documentation #3] 데이터타입과 추상화
[5] [REDIS] 📚 자료구조 명령어 종류 & 활용 사례 💯 총정리
[7] Redis 를 실무에 사용하기 전 꼭 알아야 하는 전략
※ 본 게시글의 정보가 잘못 되었거나 부족한 부분에 대한 피드백을 환영합니다.
* CopyRight 2023. Jay Park All rights reserved.